Why Understanding the Scene Matters More Than Seeing the Object
Introduction: When Pixels Are Not Enough
Most traditional computer vision systems are built around a simple assumption: if an object is visible, it can be detected. This works well in controlled environments, but real-world scenarios are far messier.
In surveillance cameras, drones, medical scans, and autonomous vehicles, objects are often small, blurred, partially occluded, or visually ambiguous. A pedestrian at an intersection may be just a few pixels tall. A medical abnormality may look like background noise. A safety helmet may blend into industrial clutter.
In such cases, seeing the object clearly is no longer possible. This is where contextual learning becomes essential.
What Is Contextual Learning?
Contextual learning in computer vision refers to teaching AI systems to understand the environment, spatial structure, and expected behavior of a scene before focusing on individual objects.
Instead of asking only “What object is this?”, a context-aware system asks:
What type of scene is this?
Where do meaningful actions usually occur?
What behaviors are likely or even possible here?
This shift allows AI to make reliable decisions even when visual evidence is weak.
Why Contextual Learning Is Critical for Detecting Small Objects
Small object detection is challenging because:
Fine visual details disappear at distance
Background patterns dominate
Noise overwhelms object signals
Contextual learning compensates by:
Narrowing down where detection should happen
Eliminating physically impossible interpretations
Adding semantic meaning to weak visual cues
In many real-world deployments, context becomes more reliable than appearance.
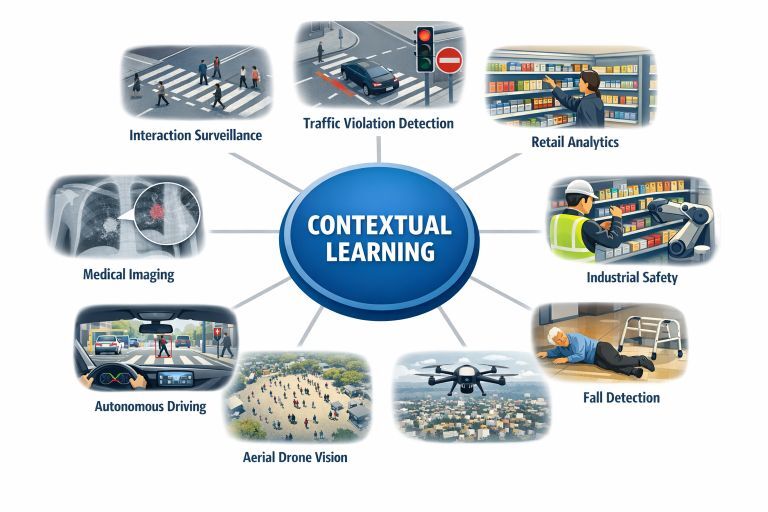
Contextual Learning in Practice: Real-World Examples (Single Unified Section)
Across industries, a common pattern emerges: when objects are small or ambiguous, context becomes the primary source of intelligence.
In interaction surveillance, pedestrians captured by overhead cameras are too small for reliable pose estimation. However, scene context such as zebra crossings, curbs, sidewalks, and traffic signals allows systems to infer behaviors like waiting, crossing, or moving in groups based on location and motion patterns rather than body joints.
In traffic and smart city analytics, violations are not visual objects but contextual events. A vehicle is considered wrong only when its motion contradicts lane direction, signal state, or stop-line rules. Context defines legality, not object appearance.
In retail and indoor analytics, hands and products are often occluded or small in ceiling-mounted cameras. Shelf layout, aisle structure, and product zones provide contextual cues that allow AI to infer browsing, picking, or returning behavior through spatial interaction with the environment.
In industrial safety monitoring, personal protective equipment such as helmets or gloves may be visually subtle. Contextual information about work zones, machine proximity, and task type determines whether safety compliance is required and whether a situation is risky.
In healthcare and assisted living, fall detection cannot rely on posture alone. Floor planes, furniture layout, and sudden changes in motion help distinguish between sitting, slipping, or falling, especially under occlusion.
In sports analytics, decisions such as offside in football depend entirely on context—field markings, ball position, and player alignment. The rule is contextual, not visual.
In aerial and drone vision, people appear as tiny dots. Crowd density, movement patterns, and anomalies are inferred from spatial distribution over terrain context rather than individual detection.
In autonomous driving, distant pedestrians may be visually unclear. Crosswalk presence, traffic signal state, vehicle speed, and road layout allow AI systems to predict pedestrian intent even when appearance is unreliable.
In medical imaging, small lesions are interpreted based on organ anatomy and tissue relationships. The same visual pattern can indicate disease or noise depending on its anatomical context.
Across all these examples, the object itself is often weak or ambiguous—but the environment provides clarity.
The Common Pattern Across All Use Cases
| Aspect | Without Context | With Context |
|---|---|---|
| Object visibility | Weak | Compensated by scene understanding |
| Detection stability | Low | High |
| False positives | Frequent | Significantly reduced |
| Reasoning | Pixel-driven | Semantics-driven |
Context transforms uncertain signals into meaningful understanding.
Contextual Learning as a Core Design Principle
Modern computer vision systems increasingly prioritize:
Scene understanding before object detection
Multi-task learning (scene, object, action together)
Temporal reasoning over isolated frames
Context-aware transformers and graph-based models
Context is no longer an optional enhancement. It is the foundation of scalable, real-world AI vision systems.
Conclusion: When Pixels Fail, Context Prevails
As computer vision moves from controlled environments into real-world deployments, perfect visibility cannot be assumed. Objects will be small, noisy, or incomplete.
Contextual learning allows AI systems to reason beyond pixels—to understand where they are, what is possible, and what matters. This shift transforms computer vision from simple recognition into genuine intelligence.
Key Takeaway
In real-world computer vision, understanding the scene matters more than seeing the object.